andrews
hai 4 meses
andrews
hai 4 meses
achega
b0049c761a
Modificáronse 100 ficheiros con 1818 adicións e 0 borrados
+ 8
- 0
.idea/.gitignore
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 8
- 0
.idea/arbitration_system.iml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 12
- 0
.idea/dataSources.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 0
.idea/inspectionProfiles/Project_Default.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 0
.idea/inspectionProfiles/profiles_settings.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 4
- 0
.idea/misc.xml
|
||
|
||
|
||
|
||
|
||
+ 8
- 0
.idea/modules.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
__pycache__/main.cpython-310.pyc
BIN=BIN
__pycache__/main.cpython-38.pyc
BIN=BIN
application_extractor/__pycache__/ocr_PP_StructureV3.cpython-310.pyc
BIN=BIN
application_extractor/__pycache__/rectify_OCR_result.cpython-310.pyc
+ 72
- 0
application_extractor/demo/PP-OCRv5/PP-OCRv5.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
application_extractor/demo/PP-OCRv5/output/F86-ZC1-2023-0001-010_00_0.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-OCRv5/output/刘正新-申请书_0.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-OCRv5/output/刘正新-申请书续_0.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-OCRv5/output/李述花-申请书_0.jpg
{kind=link}

+ 66
- 0
application_extractor/demo/PP-StructureV3/PP-StructureV3.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 52
- 0
application_extractor/demo/PP-StructureV3/PP-StructureV3_1.0.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
A diferenza do arquivo foi suprimida porque é demasiado grande
+ 4
- 0
application_extractor/demo/PP-StructureV3/output/doc_0.md
BIN=BIN
application_extractor/demo/PP-StructureV3/output/imgs/img_in_table_box_57_183_1074_1525.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-StructureV3/output/imgs/img_in_table_box_57_205_3145_2149.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-StructureV3/output/layout_det_res_0.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-StructureV3/output/layout_order_res_0.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-StructureV3/output/overall_ocr_res_0.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-StructureV3/output/region_det_res_0.jpg
{kind=link}

BIN=BIN
application_extractor/demo/PP-StructureV3/output/table_cell_img_0.jpg
{kind=link}

+ 66
- 0
application_extractor/demo/PaddleOCR-VL-1.5/PaddleOCR-VL-1.5.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
A diferenza do arquivo foi suprimida porque é demasiado grande
+ 3
- 0
application_extractor/demo/PaddleOCR-VL-1.5/output/doc_0.md
BIN=BIN
application_extractor/demo/PaddleOCR-VL-1.5/output/layout_det_res_0.jpg
{kind=link}

+ 97
- 0
application_extractor/ocr_PP_StructureV3.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 101
- 0
application_extractor/rectify_OCR_result.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 23
- 0
application_extractor/run.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
application_extractor/test/刘正新/刘正新-庭审笔录.docx
BIN=BIN
application_extractor/test/刘正新/刘正新-申请书.png
{kind=link}

BIN=BIN
application_extractor/test/刘正新/刘正新-申请书续.png
{kind=link}

BIN=BIN
application_extractor/test/刘正新/刘正新-证据清单.png
{kind=link}

BIN=BIN
application_extractor/test/李述花/李述花-劳动合同书1.png
{kind=link}

BIN=BIN
application_extractor/test/李述花/李述花-劳动合同书2.png
{kind=link}

BIN=BIN
application_extractor/test/李述花/李述花-劳动合同书3.png
{kind=link}

BIN=BIN
application_extractor/test/李述花/李述花-劳动合同书4.png
{kind=link}

BIN=BIN
application_extractor/test/李述花/李述花-庭审笔录.docx
BIN=BIN
application_extractor/test/李述花/李述花-申请书.png
{kind=link}

BIN=BIN
application_extractor/test/李述花/李述花-证据清单.png
{kind=link}

BIN=BIN
application_extractor/test/许泽用/许泽用-工伤认定书.png
{kind=link}

BIN=BIN
application_extractor/test/许泽用/许泽用-庭审笔录.docx
BIN=BIN
application_extractor/test/许泽用/许泽用-申请书.png
{kind=link}

BIN=BIN
application_extractor/test/许泽用/许泽用-申请书续.png
{kind=link}

BIN=BIN
application_extractor/test/许泽用/许泽用-证据清单.png
{kind=link}

+ 1
- 0
backend/__init__.py
|
||
|
||
BIN=BIN
backend/__pycache__/__init__.cpython-310.pyc
BIN=BIN
backend/__pycache__/api.cpython-310.pyc
BIN=BIN
backend/__pycache__/api.cpython-38.pyc
BIN=BIN
backend/__pycache__/db.cpython-310.pyc
BIN=BIN
backend/__pycache__/db.cpython-38.pyc
BIN=BIN
backend/__pycache__/embedding.cpython-310.pyc
BIN=BIN
backend/__pycache__/embedding.cpython-38.pyc
BIN=BIN
backend/__pycache__/services.cpython-310.pyc
BIN=BIN
backend/__pycache__/services.cpython-38.pyc
BIN=BIN
backend/__pycache__/text_utils.cpython-310.pyc
BIN=BIN
backend/__pycache__/text_utils.cpython-38.pyc
+ 294
- 0
backend/api.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 363
- 0
backend/db.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 33
- 0
backend/embedding.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 347
- 0
backend/services.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 80
- 0
backend/text_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
config/__pycache__/config.cpython-310.pyc
+ 7
- 0
config/config.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
evidence_extractor/__pycache__/ocr_paddle_ocr_vl.cpython-310.pyc
+ 42
- 0
evidence_extractor/demo/kaoqinbiao_ocr.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 100
- 0
evidence_extractor/ocr_paddle_ocr_vl.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 15
- 0
evidence_extractor/run.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/其他文字材料/F86-ZC1-2023-0001-009_18.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/其他文字材料/F86-ZC1-2023-0001-009_19.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/劳动关系证明材料/F86-ZC1-2023-0001-009_01.png
{kind=link}
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/劳动关系证明材料/F86-ZC1-2023-0001-009_02.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/劳动关系证明材料/F86-ZC1-2023-0001-009_23.png
{kind=link}
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/劳动关系证明材料/F86-ZC1-2023-0001-009_24.png
{kind=link}
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/劳动关系证明材料/F86-ZC1-2023-0001-009_25.png
{kind=link}
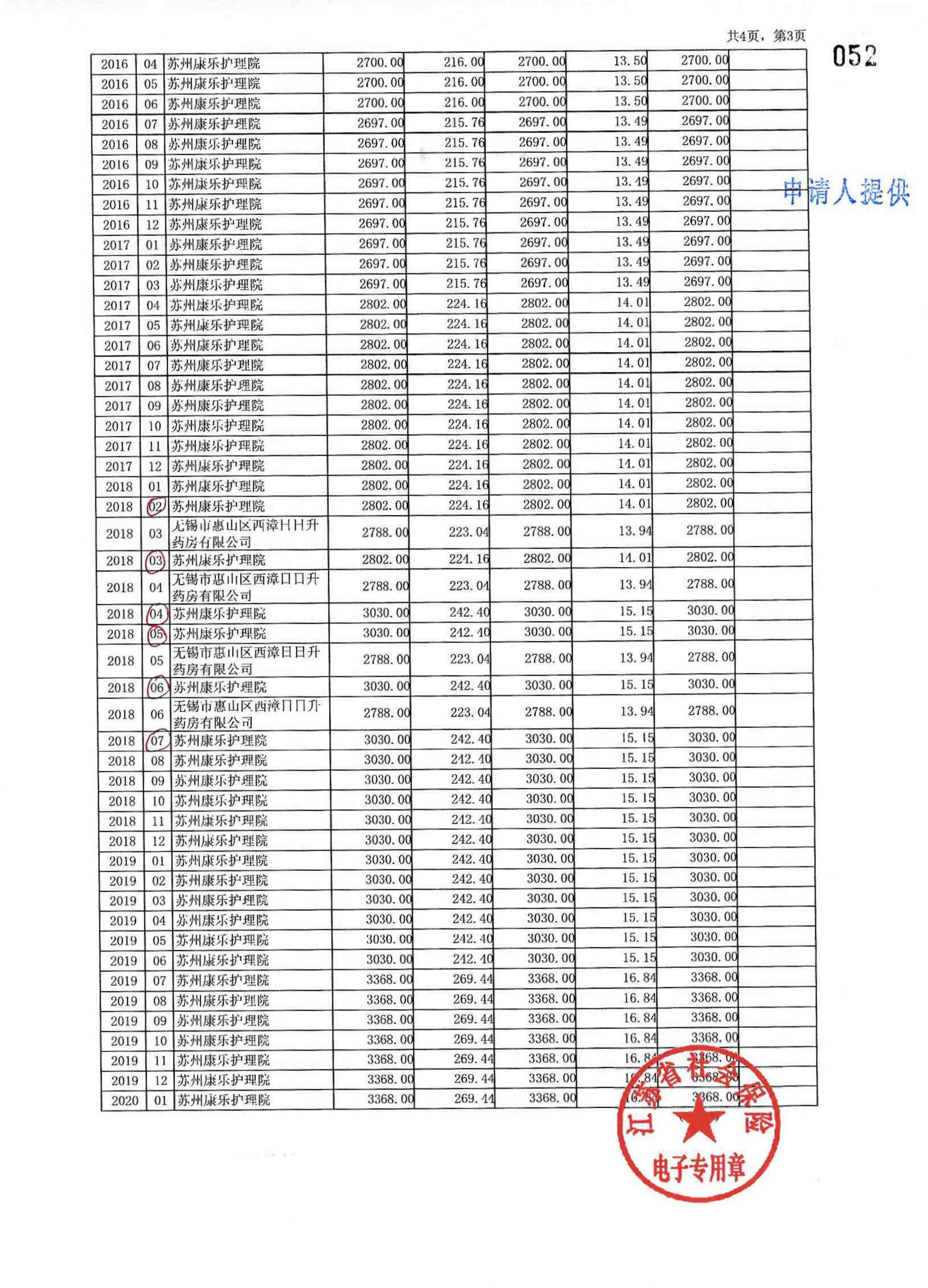
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/劳动关系证明材料/F86-ZC1-2023-0001-009_26.png
{kind=link}
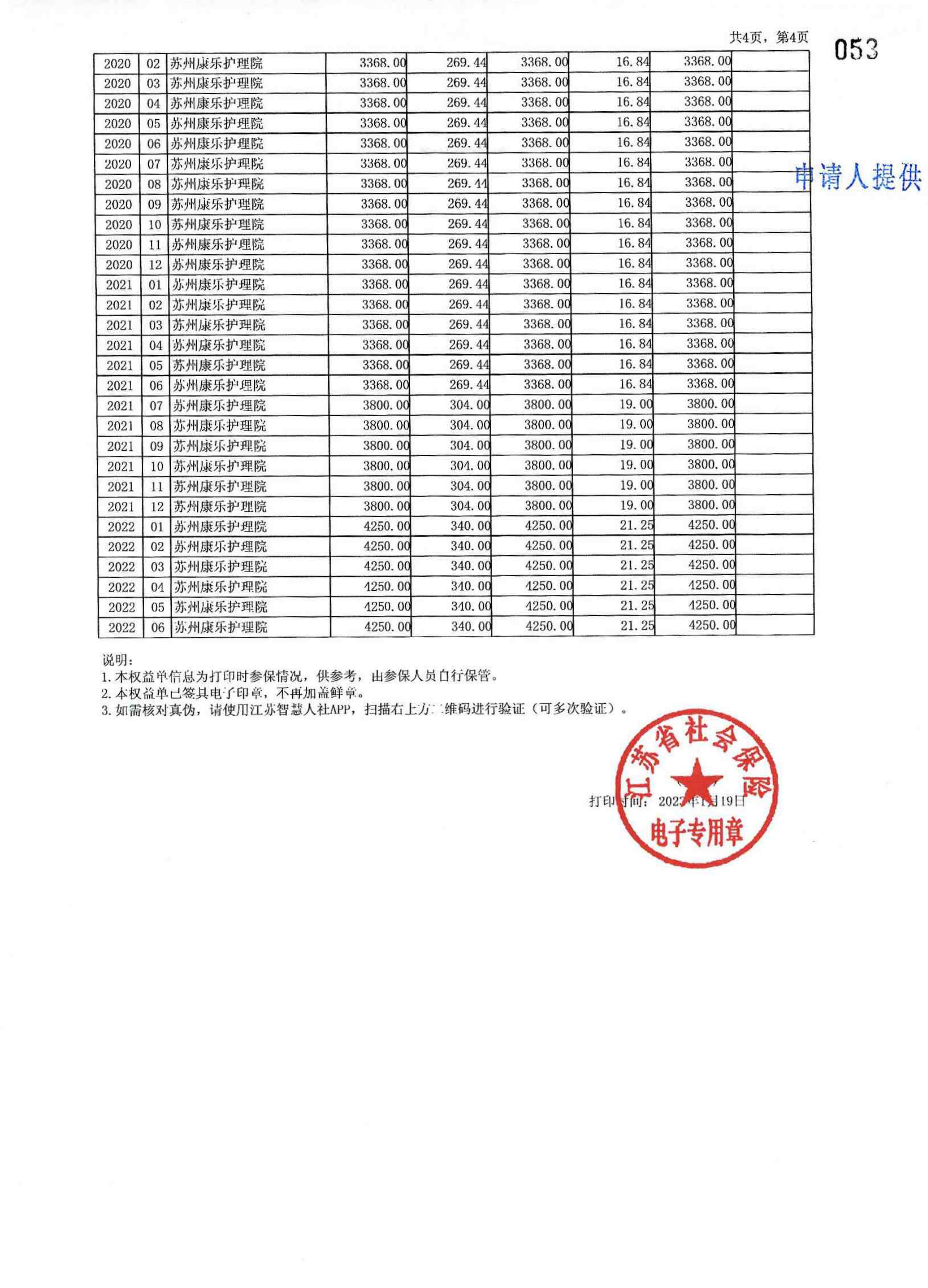
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/劳动关系证明材料/F86-ZC1-2023-0001-009_27.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/工资单/F86-ZC1-2023-0001-009_20.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/工资单/F86-ZC1-2023-0001-009_28.png
{kind=link}
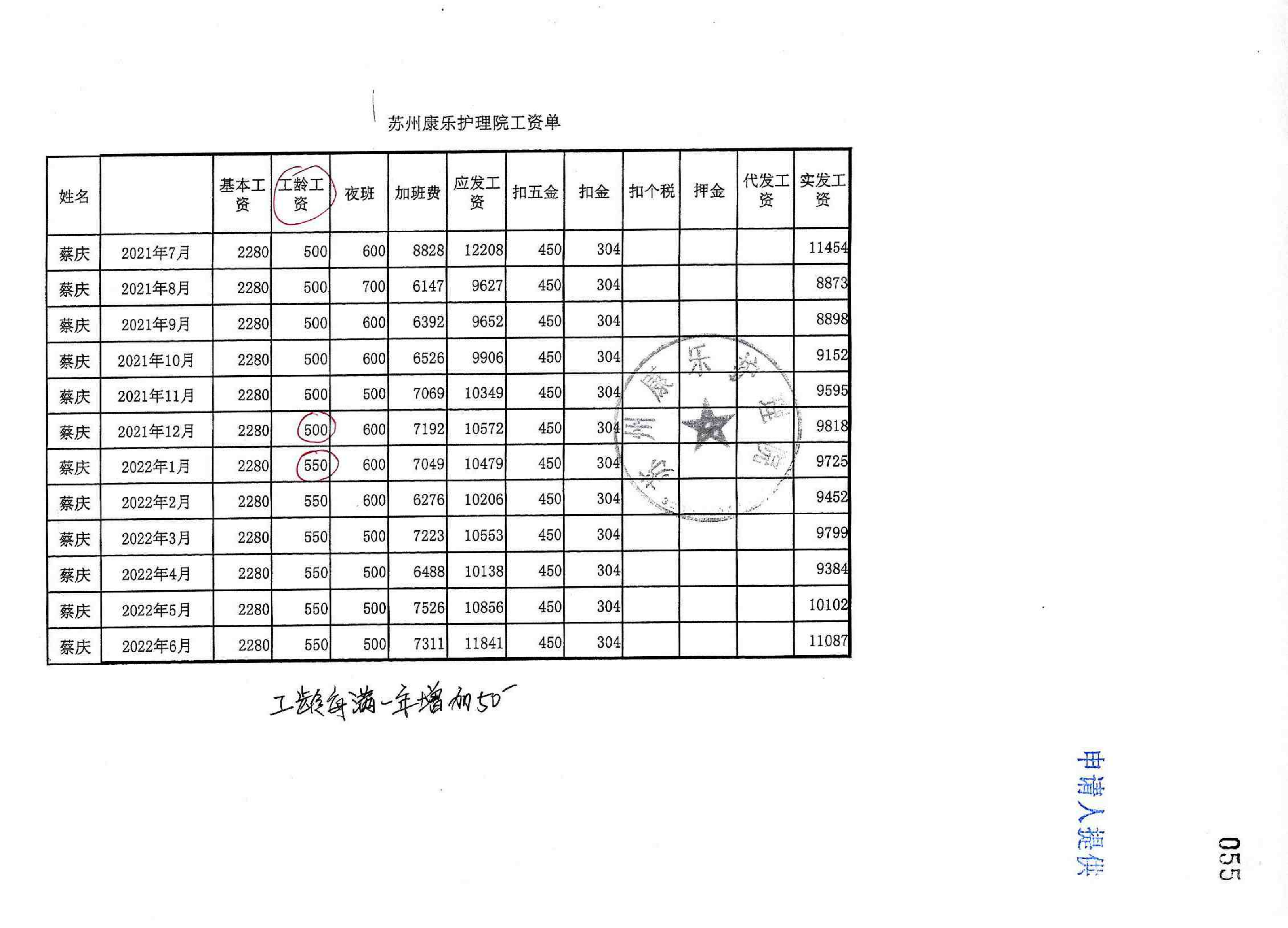
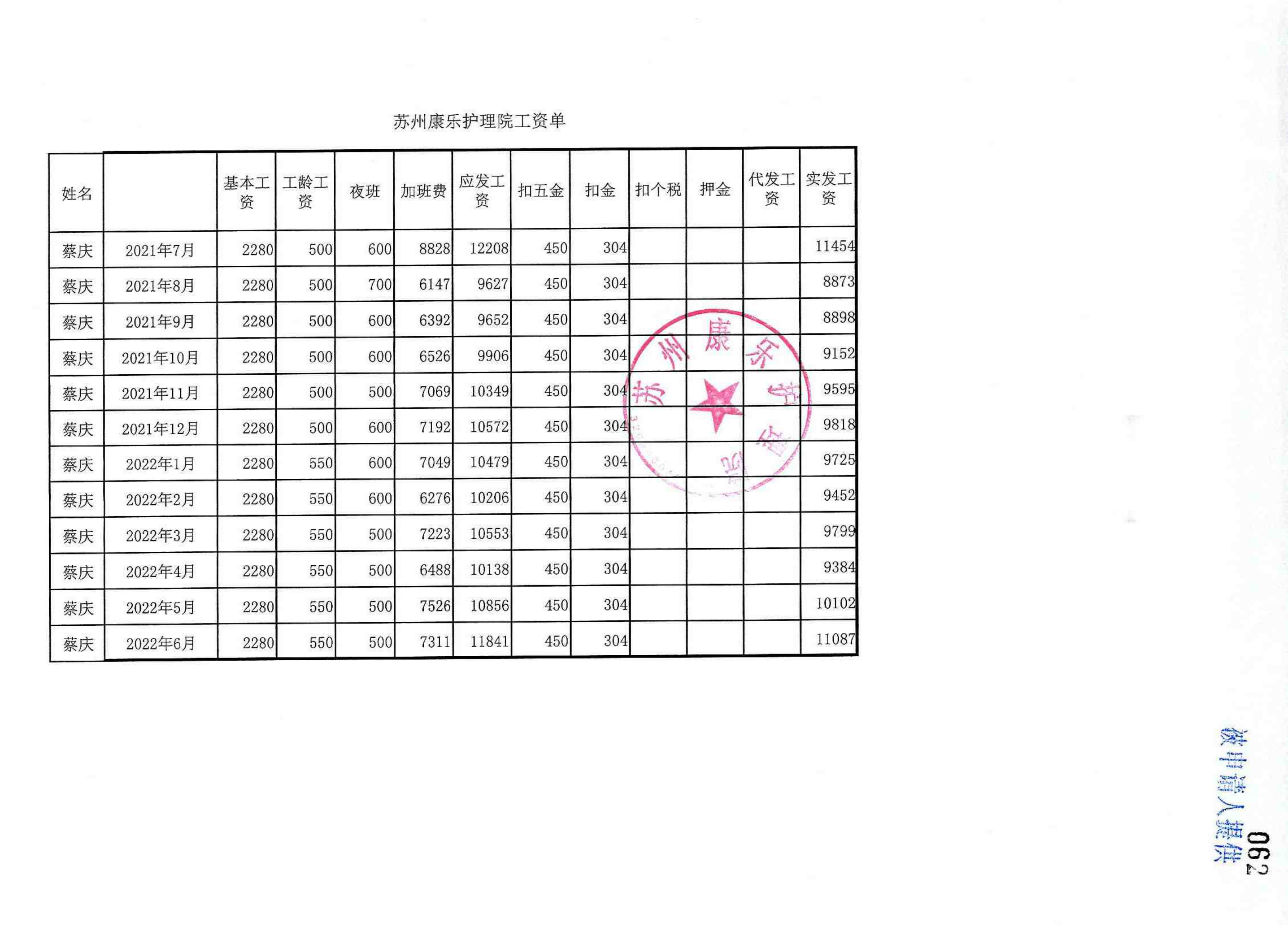
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/工资单/F86-ZC1-2023-0001-010_06.png
{kind=link}
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/考勤表/F86-ZC1-2023-0001-010_00.png
{kind=link}
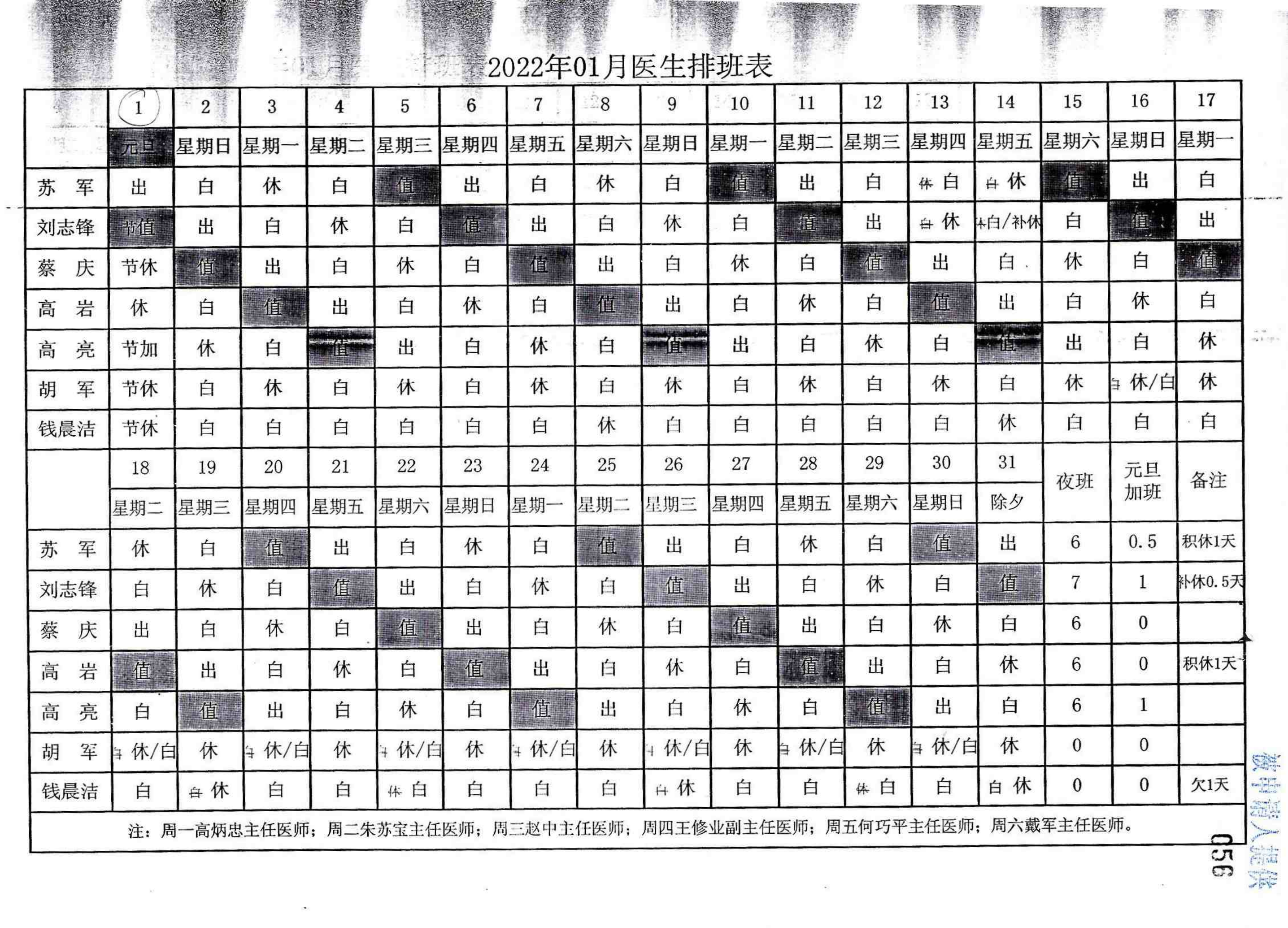
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/考勤表/F86-ZC1-2023-0001-010_01.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/考勤表/F86-ZC1-2023-0001-010_02.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/考勤表/F86-ZC1-2023-0001-010_03.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/考勤表/F86-ZC1-2023-0001-010_04.png
{kind=link}
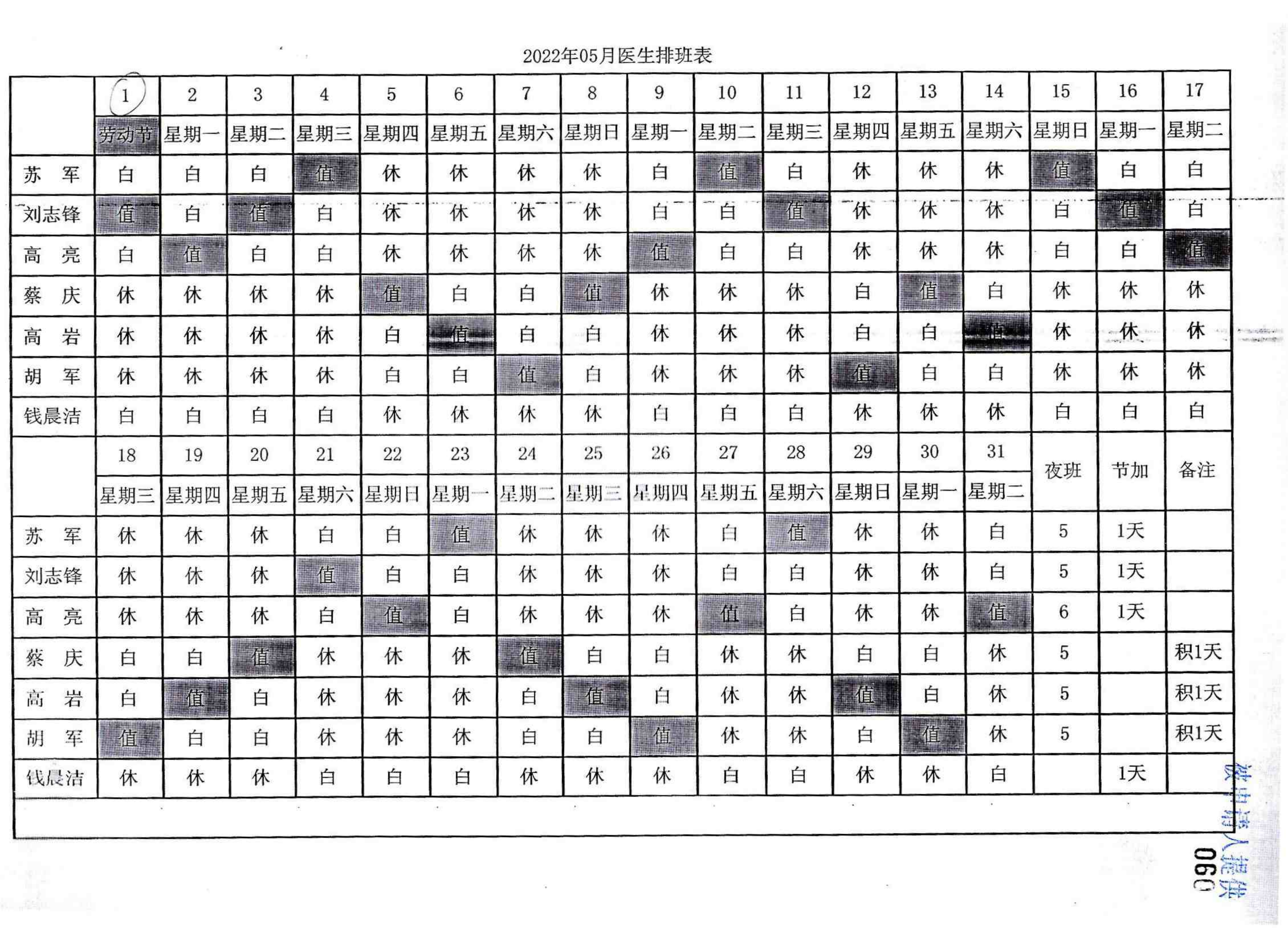
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/考勤表/F86-ZC1-2023-0001-010_05.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/解除劳动关系相关材料/F86-ZC1-2023-0001-009_03.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/证人证言/F86-ZC1-2023-0001-009_04.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/证人证言/F86-ZC1-2023-0001-009_05.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/证人证言/F86-ZC1-2023-0001-009_21.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/证据清单/F86-ZC1-2023-0001-009_00.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/证据清单/F86-ZC1-2023-0001-009_22.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/银行流水/F86-ZC1-2023-0001-009_06.png
{kind=link}
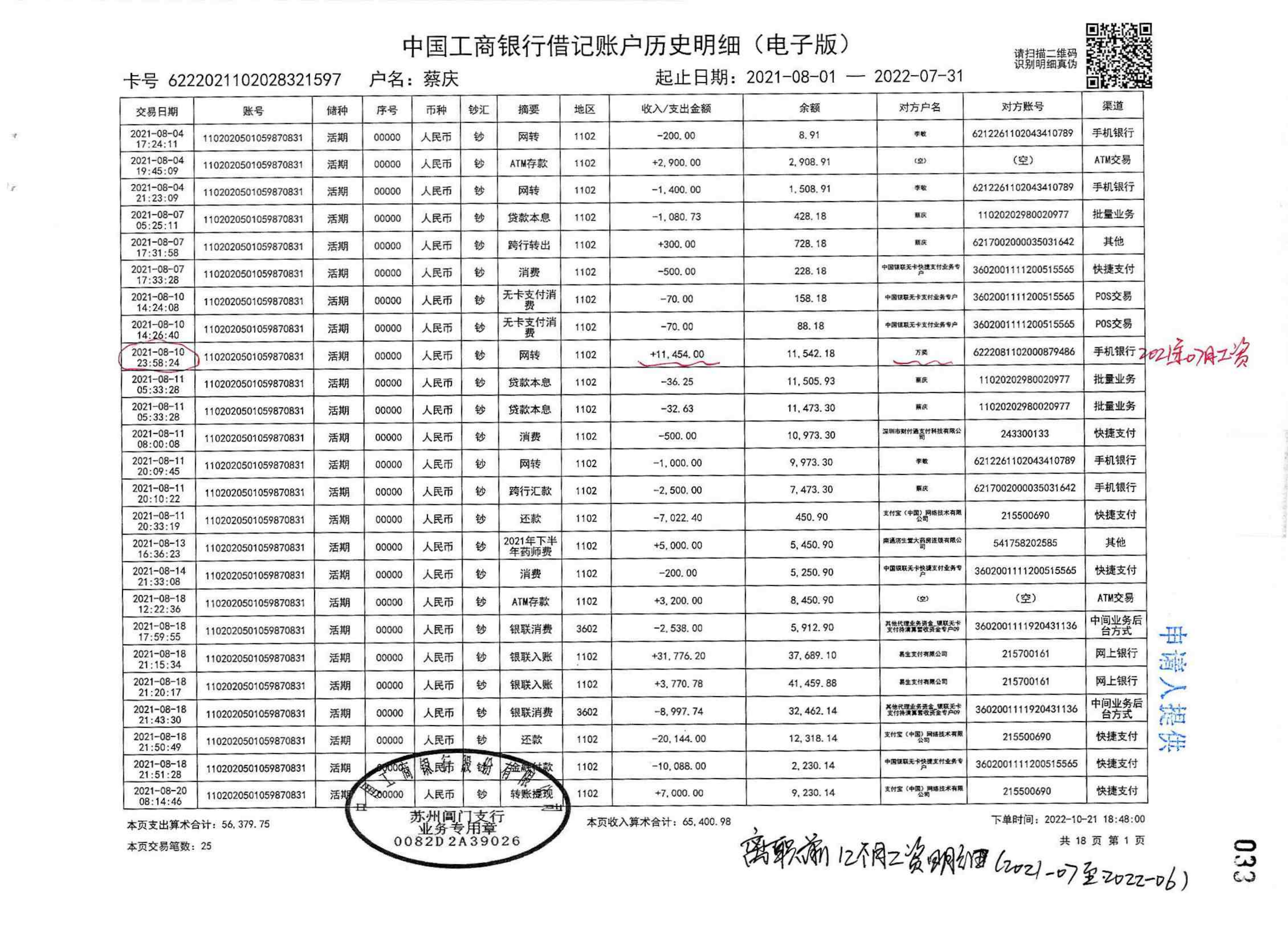
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/银行流水/F86-ZC1-2023-0001-009_07.png
{kind=link}

BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/银行流水/F86-ZC1-2023-0001-009_08.png
{kind=link}
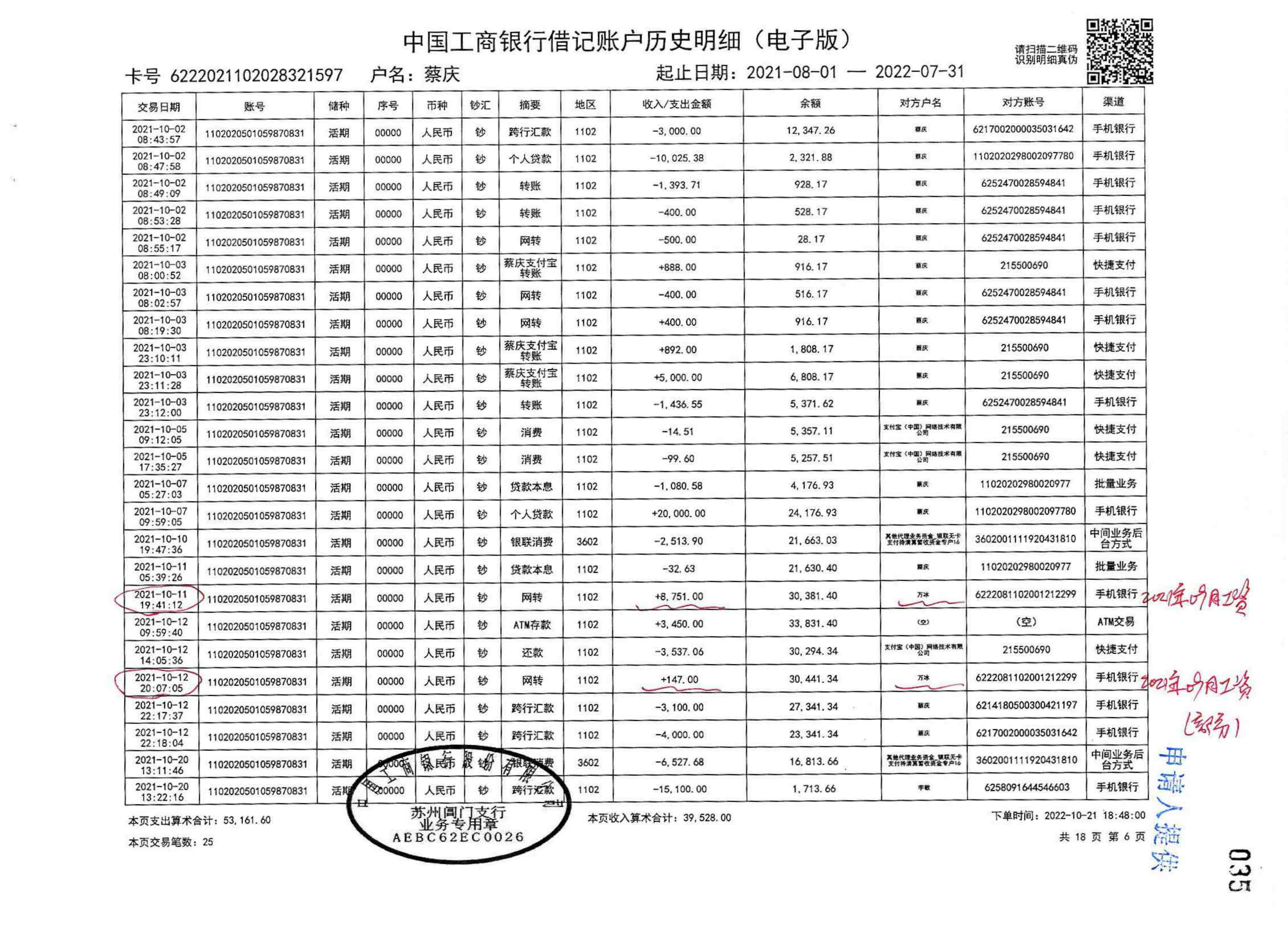
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/银行流水/F86-ZC1-2023-0001-009_09.png
{kind=link}
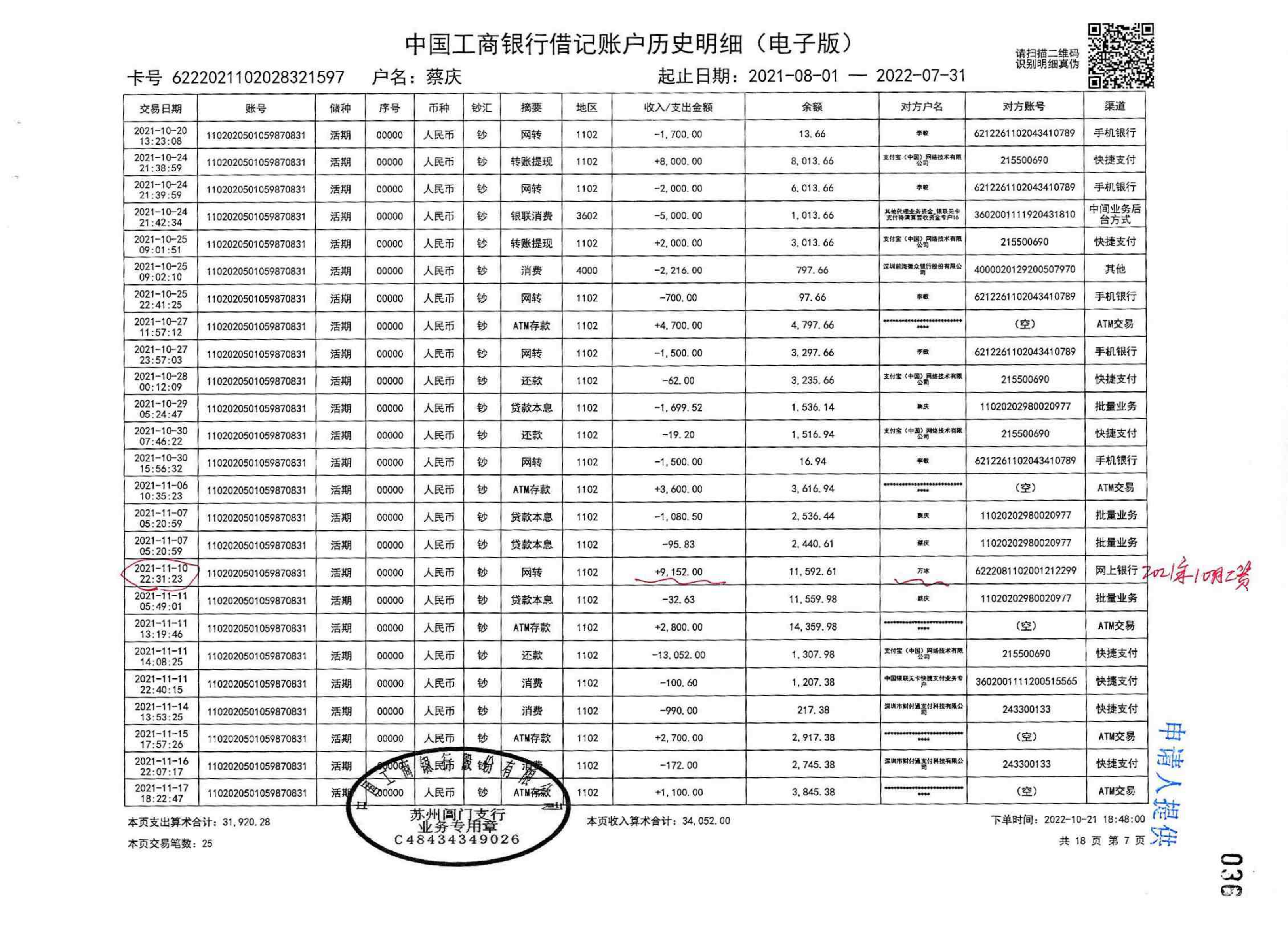
BIN=BIN
evidence_extractor/test/F86-ZC1-2023-0001/银行流水/F86-ZC1-2023-0001-009_10.png
{kind=link}